Fix: ‘Column is invalid in the select list’
The error “Column is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause” mentioned below arises when you execute “GROUP BY” query, and you have included at least one column in the select list that is neither part of the group by clause nor it is contained in an aggregate function like max(), min(), sum(), count() and avg(). So to make the query work we need to add all non-aggregated columns to either group by clause if feasible and does not have any impact on results or include these columns in a suitable aggregate function, and this will work like a charm. The error arises in MS SQL but not in MySQL.

Two keywords “Group by” and “aggregate function” have been used in this error. So we must understand when and how to use them.
Group by clause:
When an analyst needs to summarize or aggregate the data such as profit, loss, sales, cost, and salary, etc. using SQL, “GROUP BY” is very helpful in this regard. For example, to sum up, daily sales to show to senior management. Similarly, if you want to count the number of students in a department in a university group along with aggregate function will help you attain this.
Group by Split-Apply-Combine strategy:
Group by uses “split-apply-combine” strategy
- The split-phase divides the groups with their values.
- The apply phase applies the aggregate function and generates a single value.
- The combined phase combines all values in the group as a single value.

In the figure above we can see that the column has been split into three groups based on first column C1, and then aggregate function is applied on grouped values. At last combine-phase assigns a single value to each group.
This can be explained using the example below. First, create a database named “appuals”.

Example:
Create a table “employee” using the following code.
USE [appuals] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO CREATE TABLE [dbo].[employee]( [e_id] [int] NOT NULL, [e_ename] [varchar](50) NULL, [dep_id] [int] NULL, [salary] [int] NULL, CONSTRAINT [PK_employee] PRIMARY KEY CLUSTERED ( [e_id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO SET ANSI_PADDING OFF GO

Now, Insert data into the table using the following code.
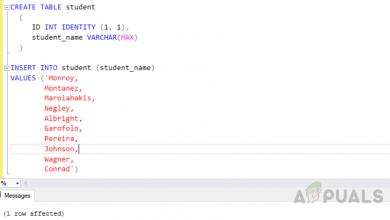
Insert into employee(e_id,e_ename,dep_id,salary) values(101,'Sadia',1,6000), (102,'Saba',1,5000), (103,'Sana',2,4000), (104,'Hammad',2,3000), (105,'Umer',3,4000), (106,'Kanwal',3,2000)
The output will be like this.

Now select data from the table by executing the following statement.
select * from employee
The output will be like this.

Now group by the table according to department id.
select dep_id, salary from employee group by dep_id
Error: Column ’employee.sallary’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
The error mentioned above arises because the “GROUP BY” query is executed and you have included “employee.salary” column in the select list which is neither part of the group by clause nor included in an aggregate function.

either an aggregate function or the GROUP BY clause.”
Solution:
As we know that “group by” return single row, so we need to apply an aggregate function to columns not used in group by clause to avoid this error. Finally, apply group by and an aggregate function to find the average salary of the employee in each department by executing the following code.
select dep_id,avg(salary) as average_sallary from employee group by dep_id

Furthermore, if we depict this table according to split_apply_combine structure it will look like this.

The figure above shows that first of all, the table is grouped into three groups according to department id, then aggregate avg() function is applied to find aggregate mean value of salary, which is then combined with department id. Thus the table is grouped by department id and salary is aggregated department wise.
Aggregate functions:
- Sum(): Returns total of each group or sum
- Count(): Returns no of rows in each of the group.
- Avg(): Returns mean or an average of each group
- Min(): Returns minimum value of each group
- Max(): Returns max value of each group.
The logical description of the use of group by and aggregate functions together:
Now we will understand the use of “group by” and “aggregate functions” logically via an example.
Create a table named “people” in the database by using the following code.
USE [appuals] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[people]( [id] [bigint] IDENTITY(1,1) NOT NULL, [name] [varchar](500) NULL, [city] [varchar](500) NULL, [state] [varchar](500) NULL, [age] [int] NULL ) ON [PRIMARY] GO

Now insert data into the table using the following query.
insert into people(name, city, state,age)
values
('Meggs', 'MONTEREY','CA',20),
('Staton','HAYWARD', 'CA',22),
('Irons', 'IRVINE' ,'CA',25)
('Krank', 'PLEASANT', 'IA',23),
('Davidson' ,'WEST BURLINGTON', 'IA',40),
('Pepewachtel' ,'FAIRFIELD' ,'IA',35)
('Schmid', 'HILLSBORO', 'OR',23),
('Davidson' ,'CLACKAMAS', 'OR',40),
('Condy','GRESHAM','OR',35)The output will be like:

If the analyst needs to know no of residents and their age in the different states. The following query will help him in getting the required results.
select age, count(*) as no_of_residents from people group by state
Error: Column ‘people.age’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
On execution of the above-mentioned query, we came across the following error
“Msg 8120, Level 16, State 1, Line 16 Column ‘people.age’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause”.
This error arises because the “GROUP BY” query is executed and you have included “‘people. age” column in the select list which is neither part of the group by clause nor included in an aggregate function.

Grouping by state arises an error
Logical description and Solution:
This is not a syntax error but it’s a logical error. As we can see that the column “no_of_residents” is returning just a single row, now how can we return the age of all residents in a single column? We can have a list of the age of people separated by commas or the average age, minimum or maximum age. Thus we need more information about the “age” column. We must quantify what we mean by the age column. By age what we want to be returned. Now we can change our question with more specific information about the age column like this.
Find no of residents along with the average age of residents in each state. Considering this we have to modify our query as shown below.
select state,avg(age) as Age,count(*) as no_of_residents from people group by state
This will execute without errors and the output will be like this.

So it’s also crucial to think logically about what to return in the select statement.
Moreover, the following points should be considered in mind while using the “group by” to avoid errors.
- GROUP BY clause comes after the where clause and before the order by clause.
- We can use where clause to eliminate rows before applying the “group by” clause.
- If a grouping column contains a null row, that row comes as a group in itself. Moreover, if a column contains more than one null they are put into a single null group as shown in the following example.
Group by and NULL values:
First, add another row into the table named “people” with the “state” column as empty/null.
insert into people(name, city, state,age) values ('Kanwal' ,'GRESHAM' ,'',35)
Now execute the following statement.
select state,avg(age) as Age,count(*) as no_of_residents from people group by state
The following figure shows its output. You can see empty value in the state column is considered as a separate group.

Now increase no null rows by inserting more rows into the table with null as a state.
insert into people(name, city, state,age)
values ('Kanwal' ,'IRVINE' ,'NULL',35), ('Krank', 'PLEASANT', 'NULL',23)
Now again execute the same query to select output. The result set will be like this.

We can see in this figure that an empty column is considered as a separate group and the null column with 2 rows is considered as another separate group with two no of residents. This is how “group by” works.